
In the world of SEO, copying content should be an obvious no-no, but many sites still run into duplicate content issues that can negatively impact search rankings. That’s because it’s actually more complicated than simply copying and pasting words onto your website and can easily happen by accident.
Simply put, duplicate content is content that appears on your website more than once. It goes beyond the copy itself being duplicated and can result from URL issues. Duplicate content confuses search engines, making it difficult to determine which is better to recommend to users in the search engine results pages (SERPs).
Keep reading to learn why it’s important to pay attention to duplicate content as well as how to fix and prevent it on your website.
Syndicated vs. Duplicate Content
Remember that duplicate content is different from syndicated content. Syndicated content is content posted by external websites, hopefully, with your permission, and is usually identifiable through proper attribution and a canonical tag. One example you might be familiar with is when PR and news websites re-post an article originally posted on a company website.
On the other hand, duplicate content often takes place on the same website unintentionally, for example, through improper programmatic SEO tactics. Programmatic SEO automates the creation of many pages for a website, which may mean that you have multiple pages on your website targeting the same topic.
Why Does Duplicate Content Matter?

Remaining mindful of duplicate content is essential due to its impact on search engines. It can lower page visibility, lessen traffic, and dilute ranking signals. Duplicate content may also negatively impact the user experience. When a website visitor encounters multiple pages with the same content, they may become frustrated and leave your website. This leads to higher bounce rates and lower engagement, negatively impacting SEO performance further.
Is Duplicate Content Penalized by Search Engines?
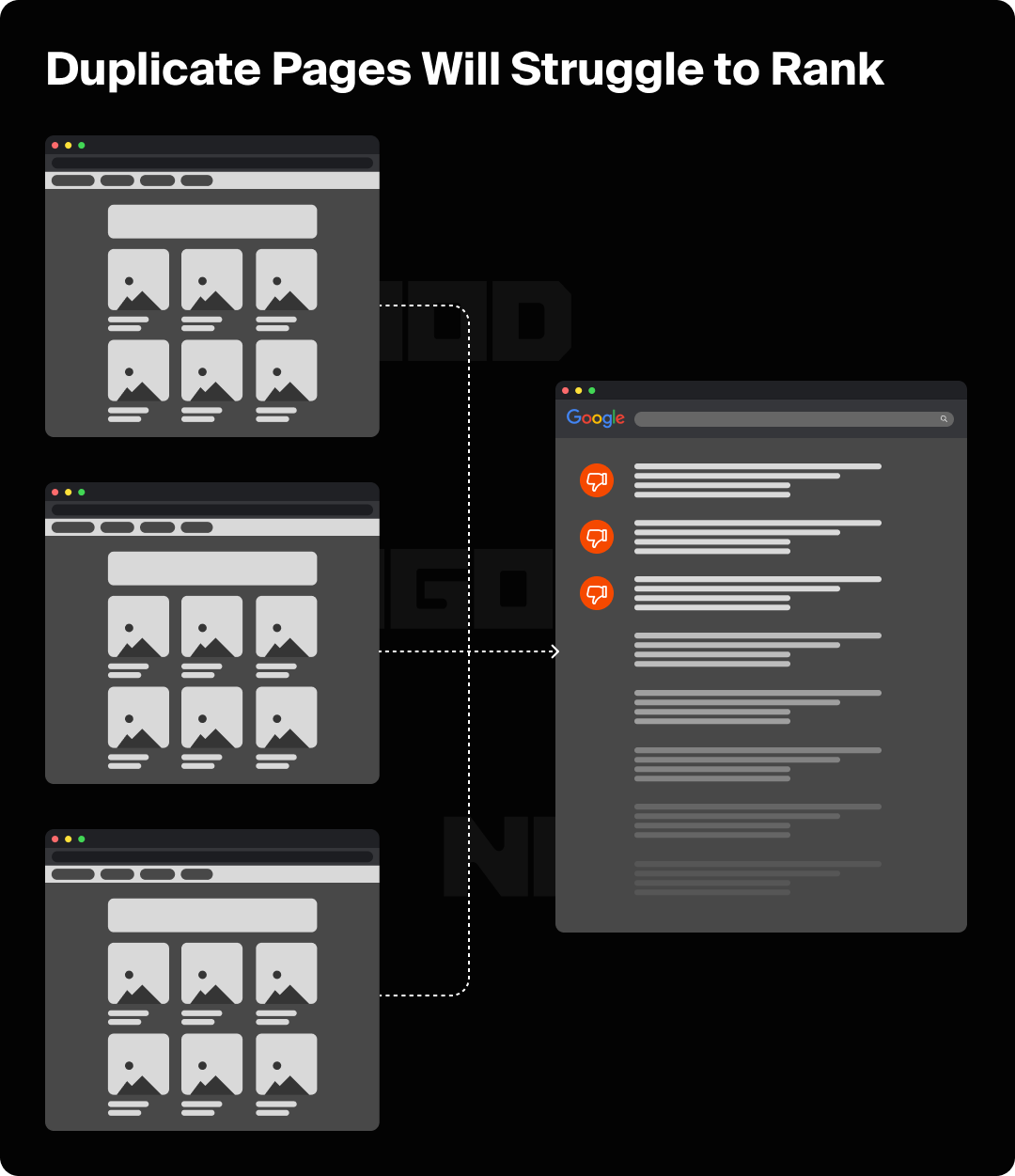
Officially, Google states that there isn’t a penalty for duplicate content; however, this doesn’t mean that duplicate content has no impact on SEO. When multiple page URLs contain the same content, it’s difficult for search engines to decide which version is better for a particular search query.
Google’s priority is to answer user queries with pages containing distinct and unique information, which doesn’t put duplicate content in the running. So while there isn’t an official penalty for websites featuring duplicate content, it certainly won’t help your rankings or traffic metrics. When Google has to pick between two of the same page, it will sometimes switch its recommendations between both, leading to volatile metrics.
It’s clear that duplicate content isn’t good for SEO, but let’s take a look at exactly how it impacts your rankings:
- Confuses Search Engines: When two separate URLs contain the same copy, search engines have a tough time deciding which will be the more helpful version for users. Because of this, it might bypass suggesting your content altogether.
- Hurts Crawling Capabilities: Having two pages means search engine crawlers have to read through each version, and because the two pages are the same, this is a waste of time and resources. More time spent trying to distinguish between the two means less time for crawlers to scan the rest of your website. Ultimately, this can lower rankings because search engines are less likely to see the overall unique value of your website.
- Dilutes Link Metrics: Multiple versions of a single page on your website result in distributing link equity between these duplicates. When search engines evaluate these variations, they have to decide which version is the most relevant and authoritative so they can recommend it in their search results. This diminishes the impact for both pages, weakening your site’s overall SEO performance.
- Impairs the User Experience: If a user hops onto your website and comes across the same information on multiple pages, it not only appears unprofessional but also makes it challenging to find the information they’re looking for. If a user doesn’t feel like they’re finding relevant or unique information, they’re likely to hop off your site in search of better resources.
Main Causes of Duplicate Content
Duplicate content often stems from human error, although technical issues can also lead to problems. Here are some of the main causes of duplicate content:
URL Variations

Different variations of the same URL can lead to duplicate content. This includes:
- Case Sensitivity: URLs with letters that differ in case may be treated as separate pages. Example: www.website.com/page vs. www.website.com/Page.
- Trailing Slash: When a trailing slash is absent in one URL but is included in another, it can create a duplicate content situation. Example: www.website.com/Page vs. www.website.com/Page/
- www vs. Non-www: If a website is accessible through both “www” and non-www versions, it can lead to duplication. Example: website.com vs. www.website.com
Localization
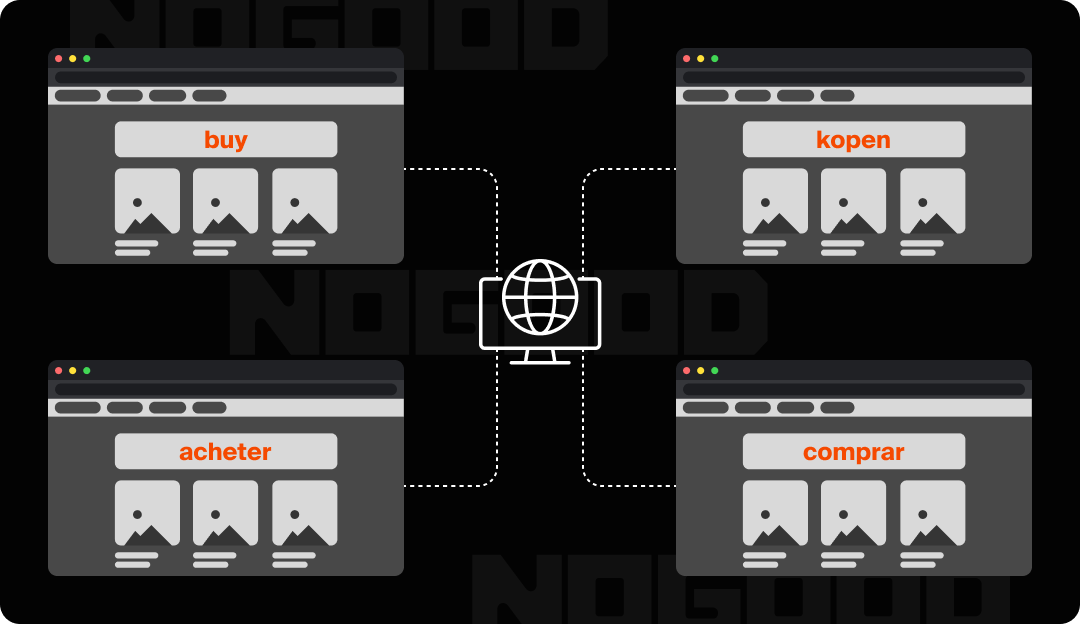
Websites with multiple language or regional versions of the same content can unintentionally create duplicate content if the translations or localizations are not managed properly.
Printable Page Versions
Some websites offer printable versions of their website. This can create duplicates of the original content under different URLs (e.g., a normal page vs. a print-friendly version).
CMS Frameworks
A content management system (CMS) is often used to streamline the creation, editing, organizing, and publishing of content. While a CMS is very helpful for websites turning out large volumes of content, it can sometimes generate duplicate content if not correctly configured. Common issues may include improperly set up pagination or category pages.
Programmatic SEO Strategies
Some businesses employ programmatic SEO tactics to scale up their content strategy. However, programmatic SEO can contribute to duplicate content issues if improperly organized.
Programmatic SEO scales content creation for a specific list of relevant keywords to a website. However, when improperly managed, this can lead to multiple pages each targeting the same or very similar keywords. This results in multiple pages with nearly identical content, but slight variations in URLs or page parameters.
Human Error
Sometimes, in our pursuit of ranking for a specific keyword, we create multiple pages targeting that keyword, hoping to boost visibility. However, this approach can lead to content that lacks enough differentiation to offer truly unique value.
When several pages target the same or very similar keywords and topics without clear distinction, it can result in keyword cannibalization. Instead of helping, these pages end up competing against each other, with search engines seeing them as essentially duplicate content. As a result, they struggle to rank, diluting your site’s overall SEO performance.
How to Check if Your Website Has Duplicate Content
There are many ways to check for existing duplicate content on your website. You can leverage Google Search Console (GSC) and refer to the ‘Coverage’ section. Scan for warnings such as “Duplicate without user-selected canonical,” which highlights pages with potential issues. You can also check the “HTML Improvements” section to spot duplicate title tags or meta descriptions potentially harming your rankings.
Another quick method is a manual Google search for duplicate content. Copy a unique sentence or paragraph from a page on your website and paste it into Google using quotes (e.g., “This is a unique sentence from your page”). This allows you to see if the exact or similar content appears on other pages within your website.
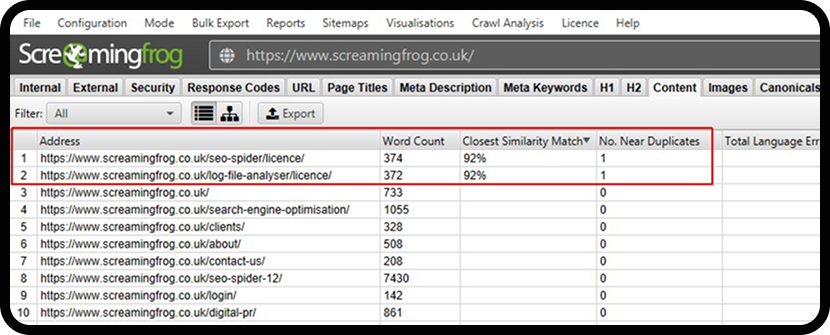
Additionally, tools like Screaming Frog can help automate finding duplicate content across your site. Screaming Frog crawls your site for issues like repeated meta descriptions or titles saving you time and giving you a clearer view of your site’s content health.
Here are some key things to look for when evaluating duplicate content issues on your website:
- Identical content on different pages (ex: similar product descriptions across multiple product pages)
- Similar content on different URLs (ex: content split across /page1, /page2)
- Duplicate title tags and meta descriptions
- Multiple URLs for the same content (ex: with URL parameters)
Fixing Duplicate Content Issues
Once you’ve identified your duplicated content, it’s important to resolve the issues before they hurt your rankings and SEO metrics further. To fix duplicate content issues on your website, you can employ several strategies. Here are some tips on how to effectively address these issues:
301 Redirect
You can use redirects to merge multiple duplicate pages, thus creating one authoritative version of the content that can be referenced. Best practices for 301 redirects indicate you should establish them from non-preferred URLs to your preferred one. 301 redirects inform search engines and website users that the content has moved permanently to a new location.
Canonical Tagging
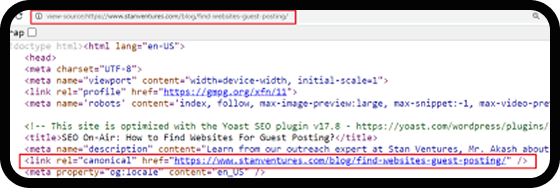
Canonical tags (rel=”canonical”) are placed in your HTML code to indicate the preferred version of a page you want search engines to display in search results. They are essential for preventing duplicate content from being indexed, ensuring that search engines recognize the original version of a page even when other similar or identical pages exist.
To implement canonical tags, add the <link rel=”canonical” href=”URL”> tag in the <head> section of your HTML documents. This tells search engines which version of a page is the preferred one to index and rank in search results. Canonical tags are particularly useful for handling problems caused by URL parameters, mobile subdomains, and AMP (Accelerated Mobile Pages) URLs, making it easier for search engines to rank the right version of your content.
By specifying the “canonical” version, these tags help search engines understand which page should be prioritized, avoiding the issues caused by having multiple pages with similar content.
“No-index” Tagging
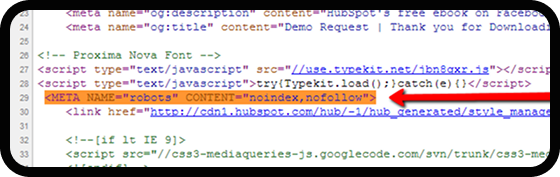
To add a “no-index” tag, place the following code in the <head> section of the HTML: <meta name=”robots” content=”noindex, follow”>. For non-HTML content (like PDFs), use the “no-index” directive in the HTTP header: X-Robots-Tag: noindex, follow.
Some pages must remain accessible on your website but should not appear in search engine indexing, – duplicate content pages or login portals, for example. By implementing the “no-index” directive within the meta tag, you can prevent these pages from appearing in search engine results while keeping them accessible to users.
While ‘no-index’ tags may appear in the same section of your code as canonical tags, they serve a different purpose. A no-index tag explicitly tells search engines not to index a page or file. This can be placed as an HTML meta tag or within the HTTP response header. The tag helps you manage which pages you want to show (or not show) in search engine results.
The ‘no-index’ tag can be especially useful in preventing search engines from indexing pages that may be duplicates or low-value variations of your primary content. For example, if you have pages with similar or identical content due to parameters, filters, or print versions, adding a “no-index” tag ensures these pages won’t compete with your primary page in search rankings, helping to protect your site’s SEO health.
Best Practices for Avoiding Duplicate Content
Configure Your CMS
If your business utilizes a CMS to help keep things organized, ensure it’s properly set up to avoid duplicate content issues. Depending on the nature of your CMS and how you’re applying it to your content strategy, there are a few ways to avoid duplicate content issues.
Some CMS tools generate session IDs in URLs. If this is the case for your system, consider disabling this feature. Session IDs can create multiple URLs for the same content. Additionally, ensure your CMS is set up to create clean and descriptive URLs without unnecessary parameters.
For paginated content (divided into multiple pages), ensure that your CMS uses proper pagination techniques. Consider using rel=”next” and rel=”prev” tags to indicate the relationship between pages.
Additionally, a CMS plugin or tool can identify duplicate content within your site. In terms of content creation, use specific guidelines or templates in your CMS to encourage authors to create unique content and avoid duplicating existing articles or pages.
Regularly Audit Your Content
Conduct regular audits of your website to identify and address instances of duplicate content. You can utilize SEO tools such as Ahrefs, Semrush, or Screaming Frog to perform a complete site audit. These tools will help identify duplicate content issues, including duplicate pages, duplicate title tags and meta descriptions, and multiple URLs for the same content.
It’s also helpful to check your indexed pages in Google Search Console. When analyzing your indexed pages, look for the number of indexed pages and the types of pages being indexed to reveal potential duplicate content issues.
Content with overlapping themes or subjects should also be revised. Even if they’re not identical, similar content can confuse search engines, so it’s better to consolidate those pieces rather than having two covering similar topics. A good final check when publishing content is to use plagiarism checkers to find unintentional duplication.
Use Sitemaps
Regular maintenance also includes submitting an updated sitemap to search engines. Your sitemap should clearly indicate the preferred versions of your pages to aid in better indexing and reduce confusion regarding duplicate content.
Generally, you’ll want to update your sitemap if you frequently add new pages and remove older ones. Submitting an updated sitemap will help search engines discover those new pages. But remember, you don’t need to resubmit your sitemap every time, just if you’ve implemented some significant changes.
Keep Your Content Fresh and Unique
To ensure your content is fresh and unique, remember to conduct your content creation process based on original research. A great way to differentiate your content is by tailoring it to different segments of your audience. By addressing specific pain points, interests, or demographics, you can craft personalized versions that resonate with each group and highlight your unique value proposition.
Additionally, once a piece of content is complete and published, it’s tempting to wipe your hands of it. However, best practices suggest reviewing and updating your existing content to reflect new information, trends, or user feedback. This can involve rewriting sections, adding new insights, or even creating new formats (like infographics or videos) based on the same topic.
Final Thoughts
Addressing duplicate content issues is essential for maintaining optimal SEO performance and enhancing user experience. While duplicate content doesn’t directly incur penalties from search engines like Google, it can dilute your ranking potential and lead to confusion among users and search algorithms.
To effectively resolve duplicate content issues, it’s crucial to implement a tailored strategy that includes the use of canonical tags, 301 redirects, and careful configuration of your content management system. Additionally, regular audits can help identify problematic duplicates, while best practices in content syndication and internal linking can prevent future occurrences.
By focusing on creating unique, valuable content for each URL and properly signaling to search engines which version of the content should be prioritized, you can ensure that your site remains authoritative and user-friendly.
Remember, there is no one-size-fits-all solution; instead, choose the methods that best align with your website’s goals and structure. By proactively managing duplicate content, you can improve your site’s visibility and ultimately drive better results.






