


Bloggers publish 116 posts per second. Read that again, slowly. 116. Per second.
The biggest problem with that number isn’t just the sheer volume (I ain’t reading all of that), but the sloppification of the internet. All of that content is probably talking about the same things, in the same way, and it reeks of AI… And if you’re writing in English? The competition is even more brutal.
I’m not saying this to scare you, but if your current strategy is to cover high-volume keywords without having anything genuinely new to contribute, you’re working with some moldy produce, my friend. Toss it and go buy a new strategy.
Unoriginal fails everyone: users, search engines, and (increasingly) AI. Google’s helpful content guidelines ask directly: “Are you mainly summarizing what others have to say without adding much value?” and “Does the content provide original information, reporting, research, or analysis?” That’s Google telling you, point blank, that originality is the path forward if you want to rank.
And while there’s no “O” in E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness), original content arguably checks all four boxes at once. Better yet, when you consistently produce original content, you’re building topical authority (much harder to gain and more valuable than keyword rankings). You’re teaching search engines that you’re a source of information, not just regurgitating what’s already being said.
The best way to do that? Original research. Studies, surveys, experiments, interviews. Real data that doesn’t exist anywhere else on the web. It can feel like a big undertaking if you’ve never done it before. Good thing you’ve got me.
Why Google Is So Obsessed With Originality
Let’s rewind a bit. A few years ago, Google was granted a patent for something called “information gain score.” This is a proprietary, legally protected system that measures how much new information a piece of content adds compared to what’s already been published on that topic.
So if you publish a blog post with original research on a topic, your information gain score would be higher than a post that’s essentially a remix of the top five results on page one. And a higher score could mean better visibility, especially for users who’ve already seen the recycled version and weren’t satisfied.
Now, does Google actually use information gain score as a ranking factor right now? Honestly, nobody knows for certain. But given how hard Google has been pushing originality as a content standard, it would be pretty surprising if they weren’t. And logically, it just makes sense. Why would Google serve a user a sixth version of the same advice they’ve already seen?
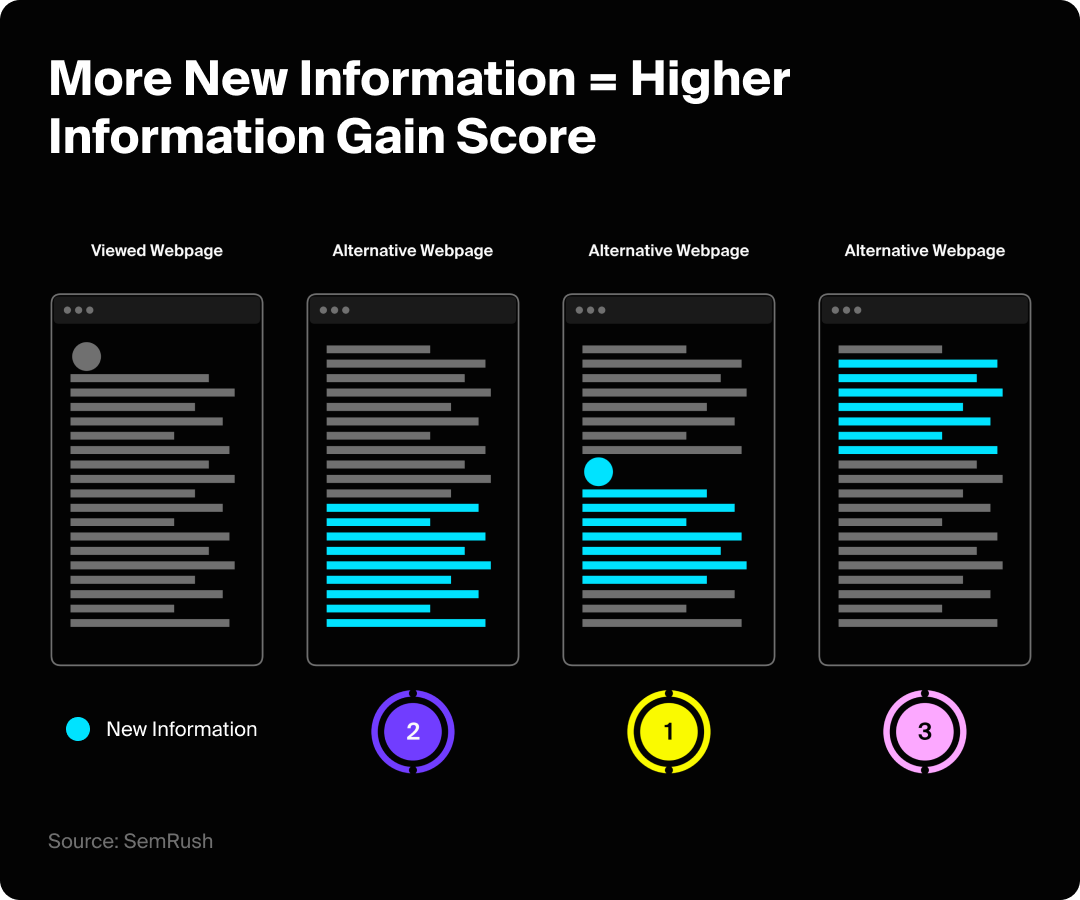
If you only take away one sentence from this article, let it be this: original research is so important because by doing it, you’re creating something that literally does not exist anywhere else on the internet.
You special little flower, you.
Becoming an Entity (Not Just a Website)
Here’s where it gets interesting. Google’s Knowledge Graph is a massive database of entities (it maps out people, places, brands, and the relationships between them). It also represents Google’s evolution from a search engine into an answer engine, which is the same shift driving the rise of LLMs.
When you consistently produce original research around a specific niche (like NoGood with B2B growth marketing or Goodie with AI visibility), Google starts to map your brand as an entity directly connected to that topic.
Think of it this way:
- Regurgitated content makes you a user of information.
- Original research makes you a source of information.
Once you become a source, you’re training the algorithm to recognize your brand as the definitive authority on that concept. Therefore, when someone asks Gemini or Perplexity a complex question in your niche, the system is more likely to look to your data for the answer.
Doesn’t sound as simple as chasing keywords, huh?
1. Find High-Value Research Gaps
Before you can conduct original research, you need to find the right topic. And the way most people approach this is actually backwards (because we just can’t let go of the SEO way to do things).
They look at the top-ranking articles and try to write something “better”. My friend, I’m here to tell you that you need to switch your mindset from “better” to “different”.
I mean, sure, go ahead and look at the top-ranking content to understand what everyone else is already saying. But then you need to go a step deeper: look for what they’re not saying, and more specifically, where they’re leaning on opinions when readers are clearly hungry for data.
Mining the SERP for Unanswered Questions
The best research topics are hiding in plain sight. When you search for a high-volume keyword in your niche, look at the “People also ask” box. Look at “Discussions and forums”. Click through those results and ask yourself: are these answers backed by actual numbers, or are they just educated guesses in sheep’s clothing?
If you spot a question in “People also ask” and the top results are offering nothing but anecdotal advice with no hard data to back it up, congratulations. You’ve found a gap.
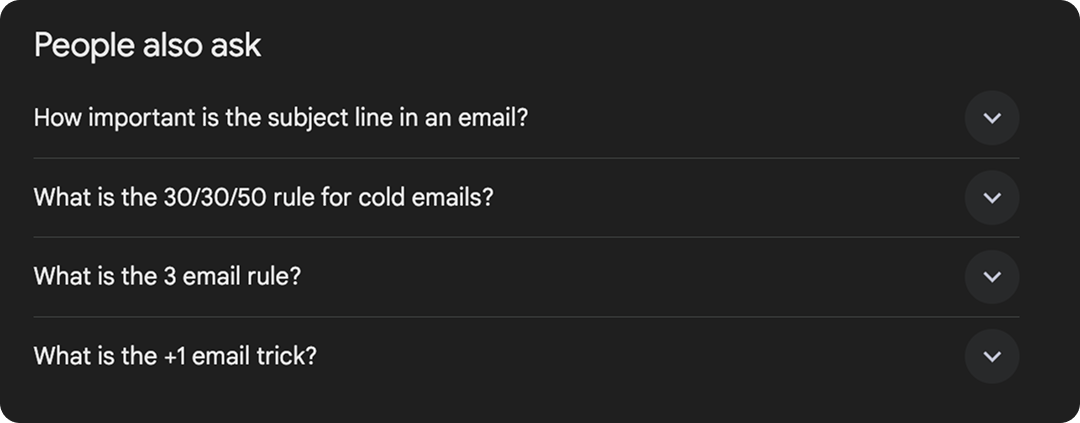
Here’s my little secret: Reddit and Quora are goldmines for this. Any time you see someone asking “Does anyone actually have data on this?” or “I’ve tried what the blogs recommend and it doesn’t work,” that’s a signal. Someone is already frustrated by the lack of original research on that topic. Go be the person who fixes it.
Pro Tip: If Reddit users are begging for proof and the best blog posts are only offering opinions, that’s your cue to conduct a study and become the source.
Running a Share of Voice Audit
Before you commit to a research project, it’s worth doing a share of voice (SoV) audit to understand how visible you are for your target keywords compared to your competitors. Tools like Ahrefs or Semrush make this pretty straightforward.
While you’re in there, pay attention to what your competitors are linking to. If every major player in your space is citing the same 2021 study from some industry giant, that data is almost certainly stale. That’s your opening. Publishing a “state of the industry” update with 2025 data positions you as the new primary source for future backlinks. Old studies are doomed to get replaced. So be the one doing the replacing.
2. Choose Your Research Type
Once you understand the landscape, it’s time to figure out what kind of research you actually want to do. The good news: you don’t need a six-figure budget or a research team. You do need to be honest about your capacity, though.
Existing Proprietary Data
This is the most underutilized option, in my opinion. If you or your clients are sitting on internal data, that’s a goldmine that no competitor can replicate. Running an email marketing campaign? Analyze a million subject lines to see which emoji combinations actually correlate with higher open rates. That’s data nobody else has access to.
Just make sure you have client consent before publishing anything, and please (I beg you) don’t forget to anonymize anything that needs to be anonymized.
Surveys & Polling
No internal data? Go get some. LinkedIn polls, Typeform, SurveyMonkey. A survey of 200 CMOs on their biggest fears for 2026 is infinitely more linkable than a listicle called “Top 10 Social Media Trends for 2026”.
It’s also infinitely more interesting to read.
Experiments & Testing
This is the scientific method applied to marketing, and it’s one of my favorites. Pick a common industry assumption and test it. Something like “we tested 500 meta descriptions to see if length actually affects CTR,” or “we tested 500 healthcare-related prompts to see what sources Claude cites most often.” The hypothesis-driven approach gives your research a clear story arc, which makes it much easier to write about later.
3. Conduct Original Research
Alright. You’ve identified your gap, chosen your research type, and you’re ready to execute. Here’s how to do it in a way that search engines, AI, and actual human readers will trust and cite.
Step 1: Write a Real Hypothesis
Before you touch a spreadsheet, you need a hypothesis. Not “I want to look at healthcare prompts”. Something specific, like: “I believe Claude Sonnet 4.6 prioritizes academic journals over government websites when responding to medical prompts”.
A strong hypothesis gives your research direction and makes it dramatically easier to write about when you’re done. If you’re stuck, go back to basics and use an “if-then” format. “If a user gives Claude a healthcare-related prompt, then it will be more likely to cite an academic journal than a government website”. Tap into your inner scientist. The more specific, the better.
Step 2: Define Your Methodology
How you collect data matters as much as the data itself. You don’t need a PhD, but you do need to be clear about your parameters:
- Sample size (10 emails vs. 10,000 emails is a very different study)
- Timeframe (when was this data collected, and between what dates?)
- Variables (what exactly did you measure, and what did you control for?)
- The “why” behind your testing approach
Include all of this under a “Methodology” section in your final piece. It doesn’t have to be front and center (let’s be real, most readers are going to skip straight to the findings), but it needs to be there. AI crawlers and search engines will index it, and it goes a long way toward signaling expertise and trustworthiness.
Step 3: Collect Your Data
This is where the heavy lifting happens. The goal, regardless of which research type you chose, is the same: precision and organization. Messy data = messy insights.
If you’re mining proprietary data, you’ll likely be working with SQL to isolate variables, and Google Sheets for aggregating and tracking disparate data points. Clean your data obsessively. Remove duplicates, filter out bot traffic, and make sure you’re only looking at what you actually set out to measure.
My pro tip here is that while LLMs are great for organizing data and creating rough visualizations, they’re… not that smart when it comes to doing math en masse. You’re gonna have to go back and forth with them, and honestly, most of the time I end up triple-checking the math old school-style.
If you’re running surveys, keep them concise and avoid leading questions. There’s a real difference between:
- Do ask: “How has the rise of AI-generated content impacted your daily content consumption habits?”
- Don’t ask: “Don’t you agree that AI slop is making it harder to find good content?”
One invites honest answers. The other just confirms your own bias back at you. Open-ended questions are also great for generating qualitative quotes you can feature in your article, which adds texture that pure numbers can’t.
If you’re running experiments, treat it like a lab report. Keep a rigorous log of every variable: the exact model version, system prompts, temperature settings, all of it. For LLM experiments specifically, I’d recommend running screen capture software while you work, so every result is documented in real time. Screenshot everything. Label your files properly. Future you will be grateful.
Step 4: Analyze & Interpret
Once you’ve got your data, circle back to your hypothesis. Does your data support it? And honestly, if it doesn’t, that’s not a failure. Actually, for those of us that like the drama, it’s potentially a more interesting story.
If you set out to prove that Claude cites academic journals for healthcare prompts and it turns out that’s not actually what happens, that’s a genuinely surprising finding. Publish it. Unexpected results are often the most cited.
Turning Your Data into Something Humans & AI Both Love
Once you have your findings, you need to present them in a format that works for your channel and for the machines indexing it.
For a blog post, go long-form and structured. For LinkedIn, distill your key finding into something a busy professional can absorb on their commute. And across every format, here are a few things that make a real difference:
- Dynamic tables and charts. Visualize your data wherever possible. Canva or Figma work great for this.
- One important note that I’ll make as an SEO by trade: if you’re using images of charts, make sure you include descriptive alt text and a brief text summary of what the chart shows (crawlers can’t always index an image).
- Downloadable assets. Offer the full report as a PDF, or the raw data as a template. This gives you a lead gen hook and signals confidence in the quality of your research.
- A TL;DR or Key Findings section. AI loves parsable, bulleted information. Starting or ending your article with a “Key Findings” summary makes it easy for crawlers to scrape your data and credit you as the source. Don’t skip this.
Using AI Without Becoming the Thing You’re Fighting Against
Yes, I’m about to tell you to use AI in a piece that’s largely about avoiding AI slop; the irony is not lost on me.
The distinction is in how you use it. AI for start-to-finish content creation? Hard pass. AI as a research and analysis assistant? Actually quite useful. Here’s where it genuinely helps:
- Data categorization. If you’ve got 500 open-ended survey responses, don’t read them one by one. Feed them into an LLM and ask something like: “Categorize these 500 responses into the top five recurring themes related to how marketers are dealing with AI content.” This is tedious work that AI does well.
- Identifying content gaps. Paste the URLs of the top-ranking articles on a topic and ask: “What specific data points or perspectives are missing from these sources that an industry professional would find valuable?” You might be surprised what it catches.
- Sentiment analysis. Use AI to scan Reddit threads or industry forum discussions at scale. This helps you frame your hypothesis around what people are actually frustrated by, not just what you assume they’re frustrated by.
What This Actually Looks Like in Practice
Our good friends at Goodie have published several blogs built around original research, and they are consistently being recognized by industry leaders for the work they do (pop off).
Take their piece on the most cited domains in LLMs. Search for “most cited domains in LLMs” on Google and here’s what you get: we populate the AI Overview. Scroll down and that same blog ranks third in the organic results.
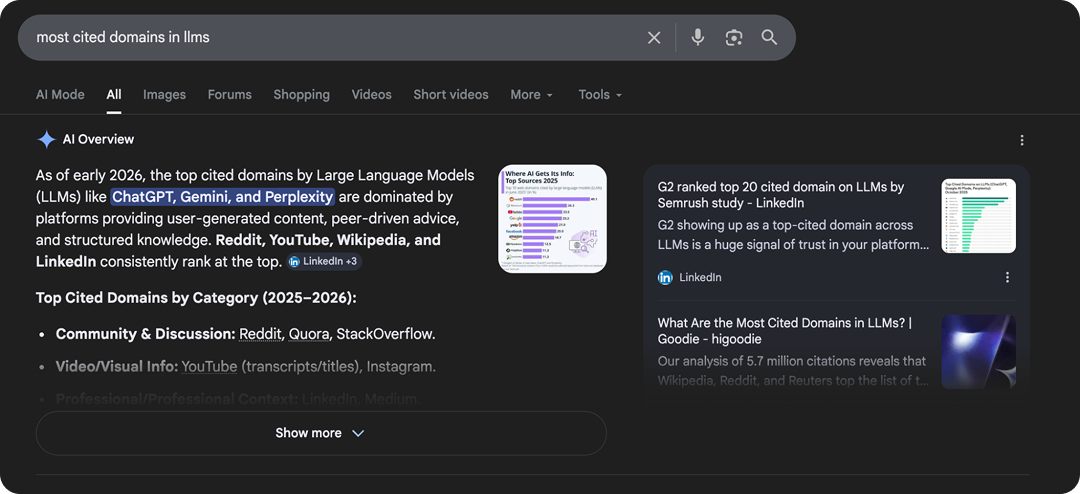
One piece of branded original research. Two distinct placements on page one.
The Only Way Forward
DO NOT TRY TO SHORTCUT YOUR WAY TO TOPICAL AUTHORITY. Sorry for yelling. I’m right, though. It’s earned through consistent effort, genuine expertise, and the willingness to produce something that didn’t exist before you made it.
The bar for publishing content has never been lower. Anyone can open ChatGPT and hit “generate”. The bar for earning trust has never been higher. Search engines, AI, and readers are getting better at filtering out static, regurgitated content. If your strategy is to summarize what’s already out there, you’re contributing to the noise. And we’re all going deaf already.
The internet doesn’t need another “social media trends you should know about” blog. It needs the data behind those trends. It needs someone willing to run the experiment, share the results even when they’re messy, and let the chips fall where they may.
The best way to be recognized as an authority by AI, search engines, and your audience is honestly pretty simple: actually be one. Do the work that other people don’t want to do. The rankings, the backlinks, and the trust will follow.